近期由于助研工作的需要,不可避免地要使用到SAS编程。其实我一开始是拒绝的,因为如果使用R,我的效率将大大提升。但是由于老师的强烈要求,不得不重新捡起已落下一年多的SAS。
理解DATA步的数据指针和PDV流程至关重要。它能帮助我们摸清DATA步中的所有执行语句是如何在缓存区,内存以及I/O系统之间转换的。或许这就是所谓的『大局观』?^_^
基本概念——数据指针和PDV
理解SAS的编译过程,需要先了解两个概念。
-
数据指针:可以理解成在当前的内存缓存区,输入数据所存储的位置;
-
PDV(Program Data Vector):在DATA步中,所有涉及的变量当前值存储在该向量(PDV)中。
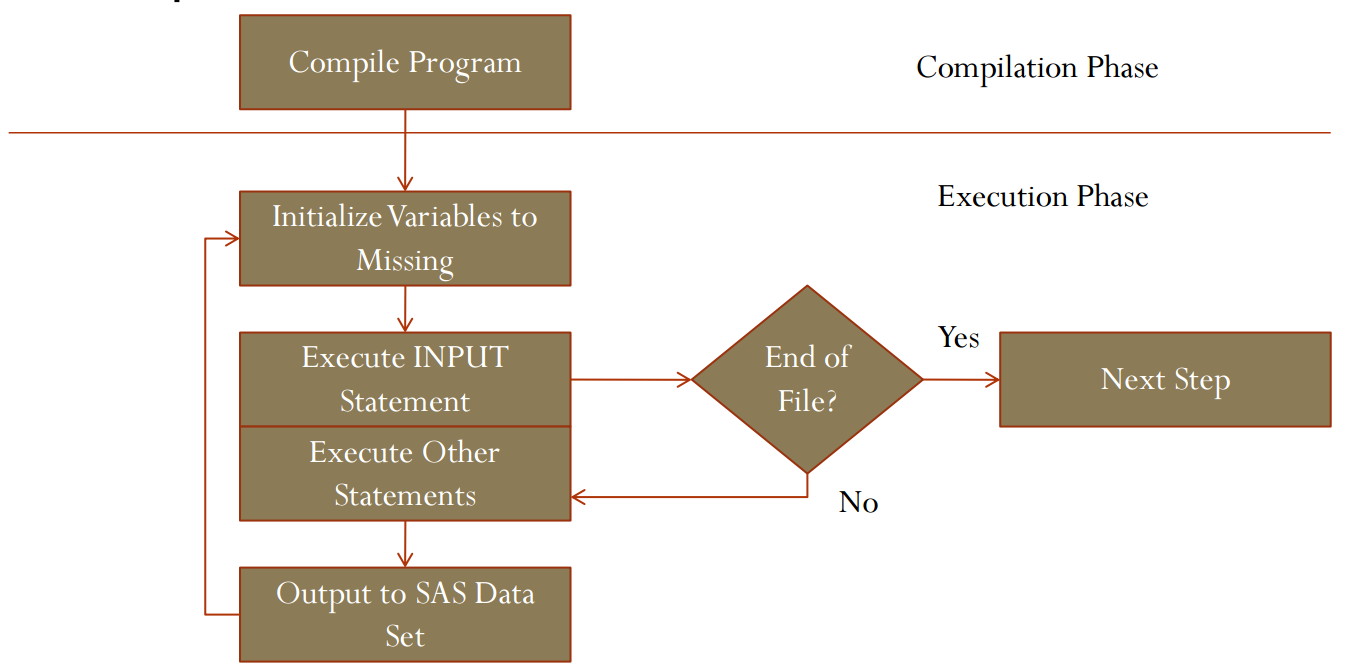
SAS程序的编译过程如下图所示:
下面,以一个简单的SAS程序为例,解释具体编译过程。
一个简单的SAS程序
data test;
input x y z;
cards;
1 2 3
4 5 6
;
run;
编译过程
-
编译程序,开辟一块内存空间给x,y,z三个变量。
-
初始化变量为缺失值。用
INPUT语句输入的这三个变量在DATA步执行之前被置为缺失值,若是RETAIN语句创建的变量,则被保留。 -
执行
INPUT语句。读入第一行观测,并把读入的数据放在PDV。 -
执行
RUN语句。将PDV中的数据输出至DATA步创建的test数据集中。 -
SAS返回到DATA语句之后的第一个语句,并初始化PDV中非
RETAIN语句创建的变量为缺失值。继续读入下一行观测数据至PDV。 -
如此循环,直至观测最后一行。结束DATA步,释放内存空间。
数据指针和PDV情况汇总
| 语句 | 数据指针数 | PDV数 |
|---|---|---|
| INPUT variables | 1 | 1 |
| SET data1 data2 | 1 | 1 |
| MERGE data1 data2 | 1 | 1 |
| UPDATE data1 data2 | 1 | 1 |
| SET data1;SET data2 | 2 | 1 |
| SET data1;MODIFY data2 | 1 | 2 |
| MODIFY data1 data2 | 1 | 2 |
自动变量
| 自动变量 | 数据指针数 | PDV数 |
|---|---|---|
| _N_ = m | 指向对应的第m条观测 | N=0表示数据集文件信息 |
| POINT = variable | 指向POINT=对应观测 | 如POINT=2表示数据指针指向第二条观测 |
| END=variable | 指向输入数据集的结尾 | |
| NOBS=variable | 输入数据集观测数 | |
| FIRST=m | 指向对应的第m条观测并开始 | |
| OBS=m | 指向对应的第m条观测并结束 |
参考文献
- 『SAS编程与数据挖掘商业案例』