RTextTools简介
古有曹植七步成诗,而RTextTools是一款让你可以在十步之内实现九种主流的机器学习分类器模型的文本分类开发包。
它集成了(或者说支持)如下算法相关的包:
-
支持向量机(Support Vector Machine from e1071)
-
glmnet(一个非常流行的用于变量选择的R包,俗称kaggle竞赛“三驾马车”之一)
-
最大熵模型(maximum entropy from maxent)
-
大规模线性判别(scaled linear discriminant,slda)
-
装袋算法(bagging from ipred)
-
提升算法(boosting from caTools)
-
随机森林(random forest from randomForest)
-
神经网络(neural networks from nnet)
-
回归树(regression tree from tree)
RTextTools有着不可不学的三大理由:
-
首先,RTextTools的设计哲学在于易学与灵活。从而,让没有任何R编程经验的社会科学研究者也能轻松实现高端的机器学习算法;并且,让经验老道的R用户充分发挥R的威力,与其他相关的包结合,如:文本预处理方面的tm包,实现LDA主题模型的topicmodels包等,实现高难度的模型,并且充分提高模型的精度等。
-
其次,RTextTools提供了从数据载入,数据清洗,到模型评价的所有功能,并且,实现的函数非常简单易记。即所谓的『一条龙服务』。
-
最后,RTextTools还可以实现结构化数据的分类问题。也就是说,它可以像普通的机器学习包caret那样使用。
下面,让我们一起来见证一下RTextTools是如何在十步之内演绎文本分类这一高端技术活的。
文本分类step-by-step
1.创建矩阵
首先,载入一个自带的测试数据集:data(USCongress)。由于RTextTools集成了tm包的功能,所以tm包在文本预处理方面的功能,如去除空格、移除稀疏词、移除停止词、词干化等功能,都可以轻松实现。
library(RTextTools)
data(USCongress)
# 看看数据长啥样
str(USCongress)
## 'data.frame': 4449 obs. of 6 variables:
## $ ID : int 1 2 3 4 5 6 7 8 9 10 ...
## $ cong : int 107 107 107 107 107 107 107 107 107 107 ...
## $ billnum : int 4499 4500 4501 4502 4503 4504 4505 4506 4507 4508 ...
## $ h_or_sen: Factor w/ 2 levels "HR","S": 1 1 1 1 1 1 1 1 1 1 ...
## $ major : int 18 18 18 18 5 21 15 18 18 18 ...
## $ text : Factor w/ 4295 levels "-- Private Bill; For the relief of Alfonso Quezada-Bonilla.",..: 4270 4269 4273 4158 3267 3521 4175 4284 4246 4285 ...
# 创建一个文档-词项矩阵
doc_matrix<-create_matrix(USCongress$text,language = "english",removeNumbers = TRUE,stemWords = TRUE,removeSparseTerms = .998)
2.创建容器(Container)
创建好文档-词项矩阵以后,下一步要做的就是对矩阵进行训练集/测试集的划分了。RTextTools中的容器(Container)概念,使得人们不必两次读入数据,而将训练集和测试集一并读入,在容器内做区分即可。
既然我们是有监督的分类算法实现,当然不能忘了指定因变量(即类别标签)。在我们的测试数据集中,类别标签为USCongress$major。
注意:类别标签一定要为数值型!
container<-create_container(doc_matrix,USCongress$major,trainSize = 1:4000,testSize = 4001:4449,virgin = FALSE)
# 看看类别个数
length(unique(USCongress$major))
## [1] 20
这里,virgin =参数的设置影响到后续模型结果的分析解读。virgin = FALSE意味着告诉R,我们的测试集是有真实的类别标签的。
3.训练模型
数据已经准备妥当,下面就可以进行模型的训练了。前面提到的九个机器学习算法的训练,只需要写成一个向量,作为参数传入train_model()函数即可同时轻松实现各种高大上的分类器模型训练。
我们来看一下train_model()函数的使用方法。
train_model(container, algorithm=c("SVM","SLDA","BOOSTING","BAGGING",
"RF","GLMNET","TREE","NNET","MAXENT"), method = "C-classification",
cross = 0, cost = 100, kernel = "radial", maxitboost = 100,
maxitglm = 10^5, size = 1, maxitnnet = 1000, MaxNWts = 10000,
rang = 0.1, decay = 5e-04, trace=FALSE, ntree = 200,
l1_regularizer = 0, l2_regularizer = 0, use_sgd = FALSE,
set_heldout = 0, verbose = FALSE,
...)
参数的设置也很简单。如果你实在懒得设置,不妨先使用默认的参数试一试。
SVM <- train_model(container,"SVM")
GLMNET <- train_model(container,"GLMNET")
MAXENT <- train_model(container,"MAXENT")
SLDA <- train_model(container,"SLDA")
BOOSTING <- train_model(container,"BOOSTING")
BAGGING <- train_model(container,"BAGGING")
RF <- train_model(container,"RF")
#NNET <- train_model(container,"NNET")
TREE <- train_model(container,"TREE")
4.使用训练好的模型进行文本分类
train_model()函数会返回一个训练好的模型对象,我们可以把该对象作为参数传给classify_model()函数,进行测试集的分类。
SVM_CLASSIFY <- classify_model(container, SVM)
GLMNET_CLASSIFY <- classify_model(container, GLMNET)
MAXENT_CLASSIFY <- classify_model(container, MAXENT)
SLDA_CLASSIFY <- classify_model(container, SLDA)
BOOSTING_CLASSIFY <- classify_model(container, BOOSTING)
BAGGING_CLASSIFY <- classify_model(container, BAGGING)
RF_CLASSIFY <- classify_model(container, RF)
#NNET_CLASSIFY <- classify_model(container, NNET)
TREE_CLASSIFY <- classify_model(container, TREE)
5.结果分析
create_analytics()函数提供了对测试集的分类结果的四种解读:从标签出发;从算法对比出发;从角度文档出发;以及整体评价。
analytics <- create_analytics(container,
cbind(SVM_CLASSIFY, SLDA_CLASSIFY,
BOOSTING_CLASSIFY, BAGGING_CLASSIFY,
RF_CLASSIFY, GLMNET_CLASSIFY, TREE_CLASSIFY,
MAXENT_CLASSIFY))
6.测试分类器准确率(accuracy)
create_analytics()返回的对象适用于summary()和print()方法。
summary(analytics)
## ENSEMBLE SUMMARY
##
## n-ENSEMBLE COVERAGE n-ENSEMBLE RECALL
## n >= 1 1.00 0.77
## n >= 2 1.00 0.77
## n >= 3 0.99 0.78
## n >= 4 0.90 0.82
## n >= 5 0.76 0.87
## n >= 6 0.62 0.90
## n >= 7 0.46 0.93
## n >= 8 0.24 0.96
##
##
## ALGORITHM PERFORMANCE
##
## SVM_PRECISION SVM_RECALL SVM_FSCORE
## 0.6830 0.6530 0.6540
## SLDA_PRECISION SLDA_RECALL SLDA_FSCORE
## 0.6530 0.6375 0.6295
## LOGITBOOST_PRECISION LOGITBOOST_RECALL LOGITBOOST_FSCORE
## 0.5955 0.6005 0.5775
## BAGGING_PRECISION BAGGING_RECALL BAGGING_FSCORE
## 0.5465 0.3905 0.4005
## FORESTS_PRECISION FORESTS_RECALL FORESTS_FSCORE
## 0.6850 0.6365 0.6415
## GLMNET_PRECISION GLMNET_RECALL GLMNET_FSCORE
## 0.6840 0.6440 0.6415
## TREE_PRECISION TREE_RECALL TREE_FSCORE
## 0.2035 0.2160 0.1795
## MAXENTROPY_PRECISION MAXENTROPY_RECALL MAXENTROPY_FSCORE
## 0.6145 0.6325 0.6190
# 为分析结果建立一个数据框
topic_summary <- analytics@label_summary
alg_summary <- analytics@algorithm_summary
ens_summary <-analytics@ensemble_summary
doc_summary <- analytics@document_summary
summary(analytics)返回了精度(precision),召回率(recall)和F-值(F-Score)等指标。这三个指标是文本分类中常用的评价指标。
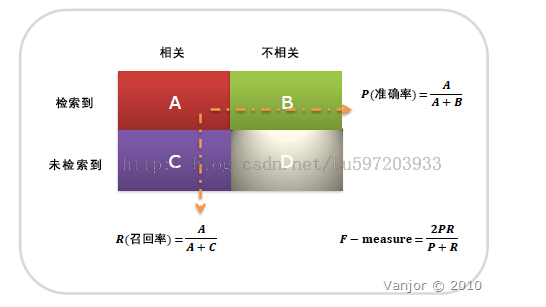
精度的定义为预测为真实正例的个数除以所有被预测为正例样本的个数。召回率则是预测为真实正例的个数除以所有真实正例样本的个数。F-值则同时考虑了精度和召回率,是两个指标的折衷。
7.整体效果评价(Ensemble agreement)
create_ensembleSummary()函数提供了整体评价功能。它反映了我们所应用的几种分类算法的『同时命中率』。
create_ensembleSummary(analytics@document_summary)
## n-ENSEMBLE COVERAGE n-ENSEMBLE RECALL
## n >= 1 1.00 0.77
## n >= 2 1.00 0.77
## n >= 3 0.99 0.78
## n >= 4 0.90 0.82
## n >= 5 0.76 0.87
## n >= 6 0.62 0.90
## n >= 7 0.46 0.93
## n >= 8 0.24 0.96
整体评价函数提供了两个评价指标:Coverage和Recall。
Coverage衡量了达到召回率阈值的文档百分比。
Coverage的定义如下:
其中,k表示满足阈值的算法个数,n代表总的算法个数。
8.交叉验证
为了进一步对比与验证各种算法的精确度,我们可以使用cross_validate()函数进行k-折交叉验证。
SVM <- cross_validate(container, 4, "SVM")
GLMNET <- cross_validate(container, 4, "GLMNET")
MAXENT <- cross_validate(container, 4, "MAXENT")
SLDA <- cross_validate(container, 4, "SLDA")
BAGGING <- cross_validate(container, 4, "BAGGING")
BOOSTING <- cross_validate(container, 4, "BOOSTING")
RF <- cross_validate(container, 4, "RF")
NNET <- cross_validate(container, 4, "NNET")
TREE <- cross_validate(container, 4, "TREE")
9.导出数据
最后,可以导出结果,对未正确标签的文档做进一步研究处理。比如,看看是哪种情形下,分类算法准确率较低,需要人工干预。
write.csv(analytics@document_summary, "DocumentSummary.csv")
结论
至此,文本分类的『独孤九剑』已然练成!然而,长路漫漫,我们要想提高模型的精度,还需要『勤修内功』,进一步学习模型的细节,加深对模型的理解,从而学会调节各种参数,进行噪音过滤,模型调整等。否则,只怕是『Garbage in, Garbage out』了。